Why Real Architecture Doesn't Fit in a Single Diagram
Most Azure architecture content shows you the same diagram. A handful of clean boxes, neat arrows running left to right, one source type, and a tidy medallion structure with raw, curated, and serving layers. It looks inevitable, like there was only ever one sensible way to lay it out.
But real platforms don't look like that.
I’ve architected Azure data platforms for defense and aviation that:
- ingest data from APIs, SFTP servers, and direct ADLS drops
- run notebooks for ingestion and stored procedures for loading
- split dedicated and serverless Synapse pools across different workloads
- serves everything through Power BI semantic models.
All while running separate dev and prod Synapse workspaces, with a small team keeping it running day to day. These platforms power data analytics and AI use cases for flight operations, survey analytics, content generation, etc.
None of that fits cleanly into a single diagram. That's the point of this article - to walk through what a real data platform looks like once it's carrying weight in production, why it’s shaped the way it is, and the operational discipline required to keep it running.
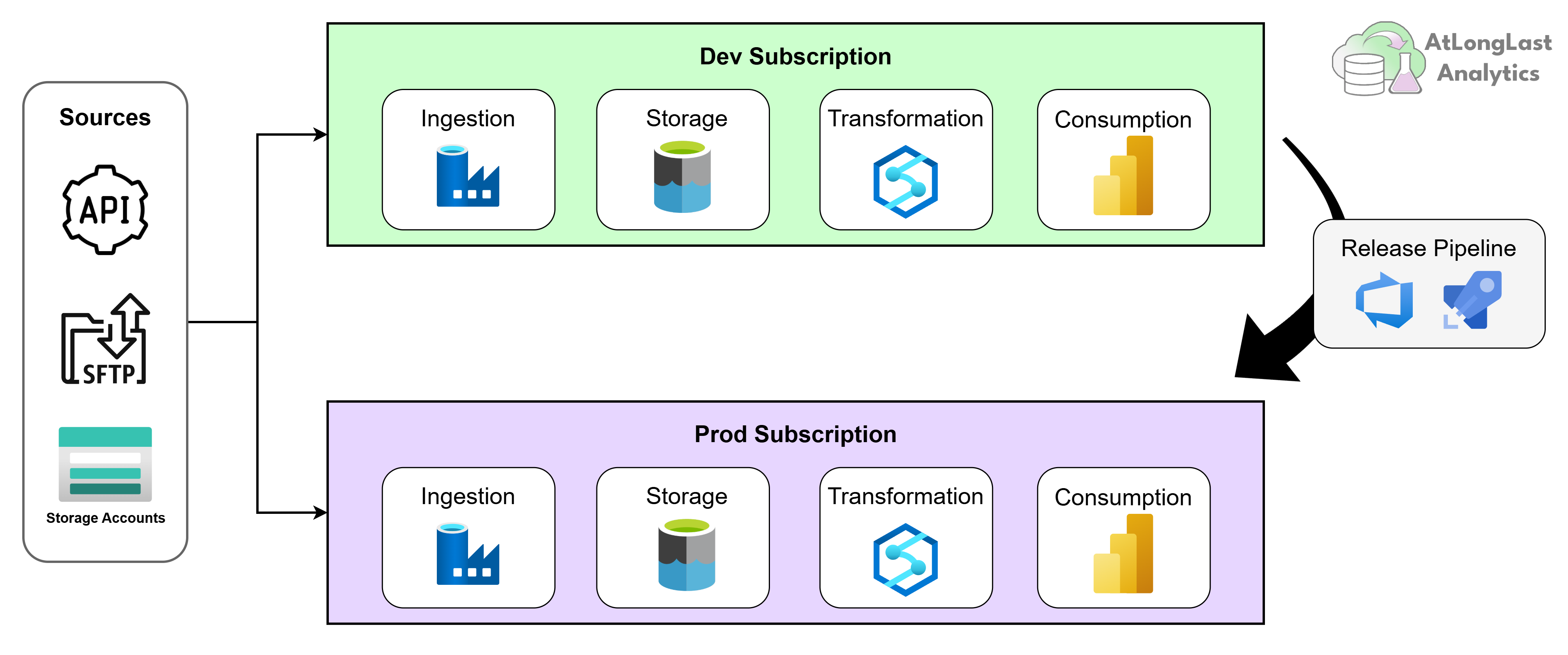
Figure 1: End-to-end view of the platform - sources (API, SFTP, ADLS) flowing through ingestion, the raw layer, transformation via Synapse, and out to Power BI, with dev and prod workspaces shown as parallel tracks.
I've written before about the gap between a secure platform and a governed one, and about what it takes to build a secure Azure data platform in the first place.
The domain sets the constraints
Complex domains like defense and aviation are not a single data problem. They’re dozens of data problems wearing the same badge.
In aviation, flight schedules update on their own clock from legacy systems; ground transportation data arrives from disparate third-party vendors; and TSA wait times flow from government systems with strict access constraints.
In defense, social scientists need to analyze surveys from different countries, each with their own terminology, digital artists require access to generative AI to create multimedia assets, and military operators need to access classified information from different sources, often as emergency response to some world event.
None of these systems were built to talk to each other, because none of them were built with the centralized data platform in mind. They were built to do their own jobs.
That's the first constraint a platform like this must absorb: heterogeneity isn't an edge case, it's the baseline. Any architecture that assumes uniform sources, file formats, or update patterns will be wrong on day one.
When the platform is late, wrong, or down, that has a direct line to operational decisions being made on stale or missing information. There's limited tolerance for "we'll fix it next sprint."
Those two pressures, source diversity and operational stakes, are what shaped almost every architectural decision that follows.
Not All Data Sources Behave the Same
It would be convenient if every source could be treated the same way. They can't, and pretending otherwise is one of the more common mistakes I see in immature data platforms.
There are three main data sources:
- APIs require built-in retry logic, schema validation, and silent-failure monitoring to combat aggressive rate-limiting and inconsistent payload updates.
- SFTP sources require treating file arrival itself as a metric. Files land on loose schedules, with shifting naming conventions and unannounced format changes.
- ADLS drops sit in between. They're cloud-native, which makes it easier to work with technically, but they often come from internal systems or partner pipelines with their own assumptions about format and frequency that may or may not be documented anywhere you can find.
Figure 2 shows the variety of data sources that you need to handle.
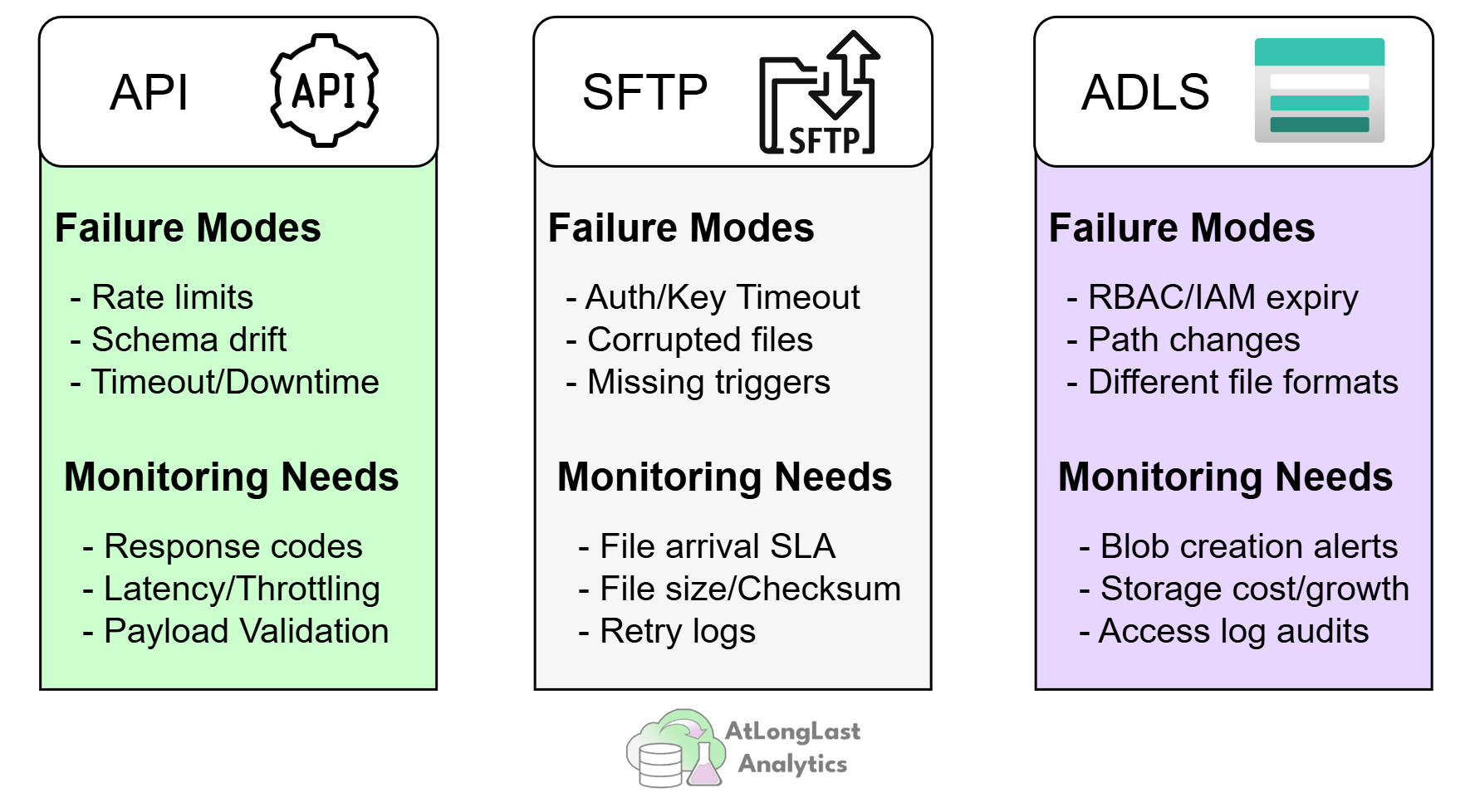
Figure 2: Three source types side by side; API, SFTP, and ADLS, showing the distinct failure modes and monitoring needs each one carries.
The pattern across all three: each source type needs its own ingestion logic, its own validation, and its own failure handling. Trying to force them into a single generic ingestion pattern just moves the complexity somewhere harder to see. Notebooks are great for API and ADLS ingestion, while Synapse pipeline activities are well suited for SFTP, specifically because they give us the flexibility to handle each source type on its own terms, while still living inside a consistent orchestration and monitoring framework.
Why You Should Split Ingestion and ETL
One of the decisions I'd defend most strongly is keeping ingestion and ETL as separate stages, with a clear boundary between them. They’re not just different scripts that happen to run in sequence, but different concerns with different responsibilities.
Ingestion’s sole job is to land immutable source data into ADLS. ETL's job (handled via notebooks and stored procedures) is to apply business logic and shape it for Synapse SQL. Separating them is key in isolating failure.
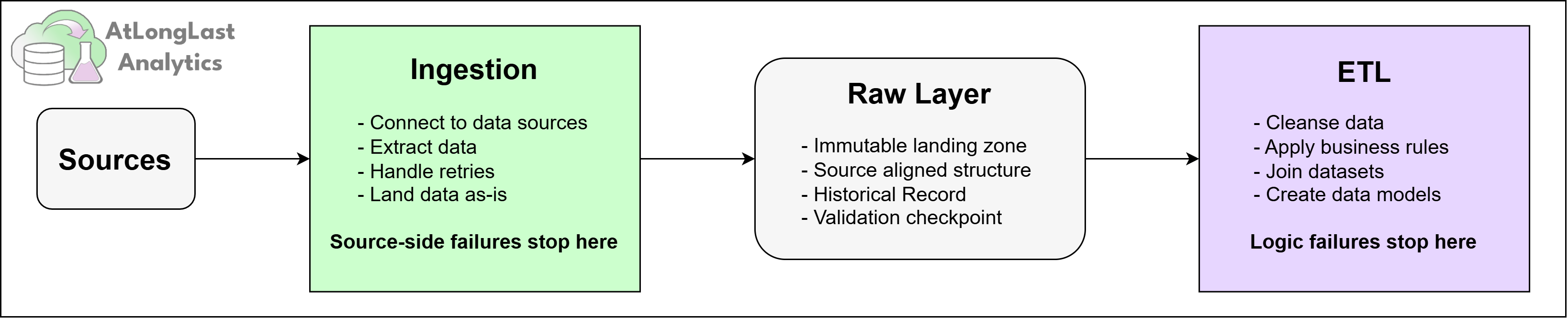
Figure 3: The ingestion/ETL boundary — what each stage owns, where the raw layer sits between them, and why that gap is where failures get isolated rather than tangled.
When something breaks, and across a dozen-plus heterogeneous sources, something eventually does, the first question is always "where did it break?". If ingestion and transformation are tangled together, that question can take hours to answer, because you're untangling both the failure and the logic at the same time. With a clean split, the answer is usually immediate: either the data didn't land (ingestion problem) or it landed but didn't transform correctly (ETL problem). This can dramatically cut debugging time.
It also means each stage can evolve independently. A new source type doesn't require touching the transformation logic. A change in business rules doesn't require touching ingestion. For a small team supporting a platform this complex, that independence isn't a nicety, it's what makes the workload sustainable.
ADLS and Synapse: dedicated and serverless, used deliberately
Synapse gives you both dedicated and serverless SQL pools, and it's tempting to treat the choice between them as a cost-optimization exercise you do once and forget. In practice, the right answer depends on the shape of the workload, and both should be used deliberately, not by default.
Dedicated pools earn their cost where workloads are predictable and performance-sensitive: the transformations and aggregations that feed the serving layer, where consistent response times matter because real people are looking at dashboards built on top of them during operational hours.
Serverless pools fit the more exploratory, ad hoc, or infrequent workloads; querying directly against data in ADLS without the overhead of provisioning, useful for investigation, validation, and lower-frequency processing where paying for always-on compute would be wasted spend.
The data sitting underneath both is in ADLS, structured so that both pool types can reach it appropriately depending on what's being asked of it. Getting this split right takes some iteration, you won't land on the best allocation on the first attempt, and it's a decision that's worth periodically revisiting as workloads shift, not something to set once and assume will stay correct.
Dev and prod as a real discipline, not a checkbox.
Running separate dev and prod Synapse workspaces sounds like an obvious best practice, and on paper, it is. What's less obvious is what that separation actually buys you once you're operating day to day, and how easily it erodes if you don't actively maintain it.
The real value isn't just, "we have an environment to test in", it's that changes to ingestion logic, transformation rules, or schema can be validated against realistic conditions without putting live operational reporting at risk. When something does go wrong in prod, you have a clean environment to reproduce and diagnose the issue without contaminating it with the very problem you're investigating.
For a small team, this discipline also does something subtler: it forces decisions to be made explicitly rather than slipping through. A change that needs to be promoted from dev to prod is a change someone consciously decided to ship. Over time, that habit is what keeps a platform's behavior intentional rather than accidental.
It does require real discipline to maintain, keeping the environments meaningfully aligned, making sure the promotion process is actually followed rather than bypassed under deadline pressure, and resisting the temptation to patch prod directly "just this once." That temptation shows up more often than anyone would like to admit, especially when something operational is on fire and the fix is two minutes away in prod versus twenty through the proper path.
What this looks like running
On a good day, the platform is mostly invisible. Notebooks pick up sources on schedule, stored procedures run their transformations, semantic models refresh, and the people relying on operational dashboards or reports never think about any of it. That invisibility is the goal, when a platform is working, nobody notices it.
On a bad day, it's a file that didn't arrive from an SFTP source because someone changed a naming convention upstream without telling anyone. It's an API that quietly changed its response schema between releases. It's a stored procedure that ran successfully but produced numbers that were subtly wrong because an upstream assumption no longer held. None of these show up as a system being "down." They show up as numbers that look slightly off to someone who knows what the numbers should look like, which means catching them depends as much on monitoring and on people as it does infrastructure.
If I were starting platform design over today, a few things would change. I'd push harder, earlier, on monitoring that catches "the data arrived but looks wrong" rather than just "the job failed". That category of failure is by far the more common one, and the harder one to detect after the fact. I'd also be more deliberate about documenting the assumptions baked into each source's ingestion logic, because those assumptions are exactly what breaks when an upstream system changes something it considered minor.
What hasn't changed is the core shape of it: separate ingestion from transformation, treat each source on its own terms, keep dev and prod genuinely separate, and choose compute intentionally. Those decisions have held up under real operational pressure, across a diverse set of sources, with a small team keeping it running.
Final thoughts
Architecture diagrams are a useful starting point, but they're a model of the platform, not the platform itself. The real thing accumulates edge cases, legacy quirks, and hard-won lessons that never make it into the picture, and that's not a failure of the design. It's what happens when an architecture meets the real world and has to keep working anyway.
If you're building or operating something with this kind of source diversity and want to talk through how the pieces fit together, or where yours might be straining - let's talk.